Azure ML? Seriously? Yes. Seriously!
Introduction
I have been working full time on Data Science since mid 2017 (5 years). During that time, I have made just about every ML mistake you can think of.
- Use training data in the test set? Yup.
- Created a great deep learning model only to loose track of the model file and have to retrain? Sure.
- Tried to retrain a model, but couldn’t re-find the hyperparameters that worked well? Done that.
- Used an open source autoML package that was based on Java and used Log4J that was shown to have major security flaws and then forced to retrain the autoML model again, but I still cannot remember what the first autoML model settled on? Yeah.
- Ran an inference model on a bare-metal EC2 instance that mostly sat idle, but has to have a boatload of RAM so it is way more expensive that it should be, even if it only “wakes up” part of the time. Yeah.
Heck, I am not proud, I can even say that I wrote a MONSTER single-threaded-and-super-slow python app that sucks data out of a cloud data service, chugs on it, and then shoves the results back into the cloud data service… from scratch.
So, yeah. I have made a ton of mistakes. In December, I completed my MS in Analytics from Georgia Tech. (See my earlier post.) That program helped me begin to understand what professional analytics is about. It turned me onto techniques like EDA, simulation, cross-validation, and feature engineering. I learned and relearned about the math and statistics of why things work, and why they sometimes don’t. My masters courses also helped me learn about behaviors and best practices that help reduce the likelihood of making process and workflow mistakes. But, even after all that, doing analytics and data science is hard. Doing it well, is very hard.
I am so happy that Microsoft has helped make it a little easier.
Now, if you would have said to me that I would write that line 5 years ago, I would have said you were crazy. I have used Microsoft products in the past, but it has always been with some reluctance. I don’t typically run Windows unless I cannot avoid it (I prefer to use Linux, or a Mac.) Being a certified Novell Network Engineer (CNE… you young kids can just Google that), I never quite got over the fact that Microsoft basically killed Novell.
I was somewhat skeptical when, in my current job, I found myself faced with evaluating Azure ML. I must say that Microsoft has done a very nice job of Machine Learning Platform as a Service. Add to that how far Azure has come… Well, if you’re working in Analytics or Data Science, it might be well worth your time to check out the platform. And… you can try it out for free!
Still need to be convinced why MSFT has developed a winning solution for analytics? Ok. I respect that. Let me offer a few details to consider. I’ll break this down relative to how I tend to think of the analytics process…
- Data
- Exploratory Analysis
- Model Training
- Experiments
- Model Training With MASSIVE Data
- Model Management
- Model Deployment and…
- Data
That said, lets begin with data…
Data
As you maybe guessed from the above, I believe that data science and analytics literally begin and end with data. It is really crazy to me how so many data science platforms don’t really do data justice. Azure ML has this covered by seamlessly integrating data into the ML environment. You can see this in the Azure ML Studio. If you are not familiar with Azure, and are with AWS (as I was) it works in sort of the same paradigm. Azure has a TON of services that they offer through their portal. (My favorite joke about AWS is that if Voldermort really wanted to hide a horcrux, he would have done it in the AWS portal.) Azure ML Studio makes using the various services involved in Azure ML easy. They have really simplified the “searching for the horcrux” problem well with ML Studio.
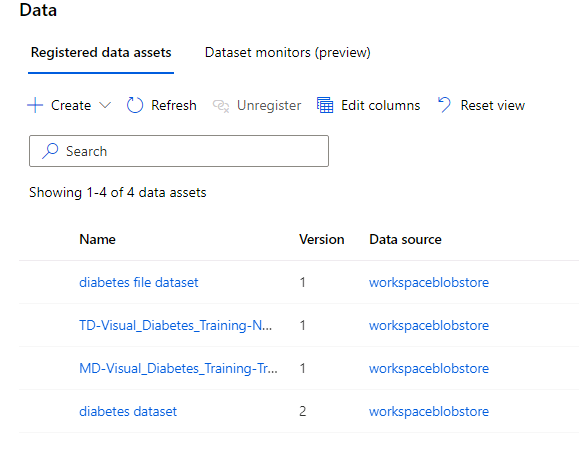
Accessing data in Azure is done with datastores and datasets. Datastores provide seamless access to data hosted in Azure in the form of blob storage, files, data lakes, SQL, Postgres and MySQL databases. Datasets are versioned sets of data used primarily for training models. ML Studio makes it seamlessly easy to find and use data you need for training models. I really like the fact that can VERSION data sets. Knowing what DATA you used to train a model is critical. Change the training data, and of course you are going to change the model. This is something that I don’t think is addressed enough. Sure, it is important to know your model hyperparameters… but what DATA you use to train the model is an equally important question.
Exploratory Analysis
Once you have data, a critical first step is to actually look at it. This is something that was really stressed in several of my Masters classes, and I agree. Don’t just assume that your data file is correct. ACTUALLY LOOK AT IT. This is easy in Azure ML Studio.
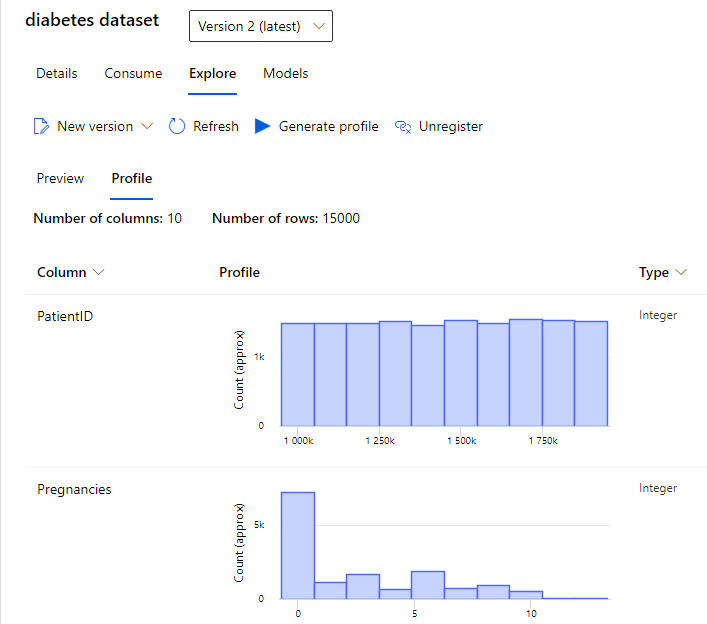
If you’ve imported the data, you can simply view the data. You can also generate a dataset profile, which will provide some nice basics descriptive statistics and graphs for your data set. You could do this in a jupyter notebook easily enough… but with Azure, you don’t even have to do that.
Model Training
Once you have understood your data, you will eventually want to start building some models. Azure ML Studio uses the Jupyter notebook paradigm. You can mix code and documentation in these notebooks as you would expect. The other option with Azure is to use their “no code” (which is really low code) training pipeline “Designer”. I remember when we looked at this in grad school, and one classmate commented on just how easy and intuitive using the Azure ML designer was for this purpose.
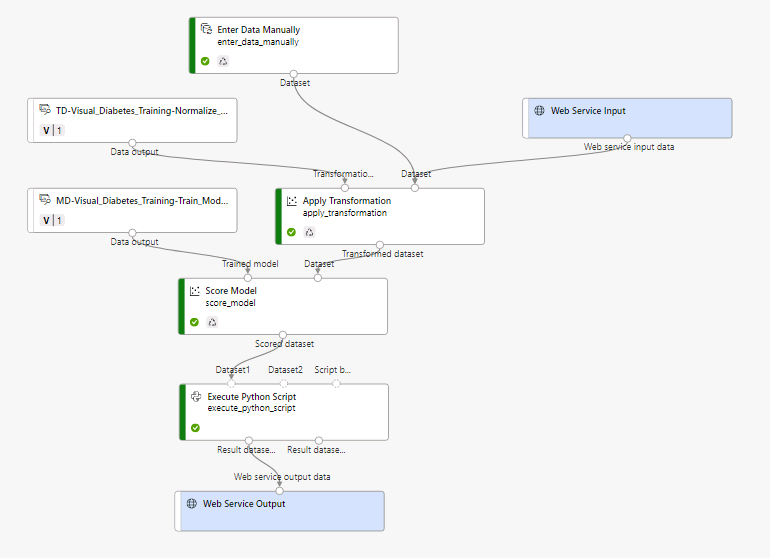
If you are looking to build a simple regression model, or a K-MEANS, or even a boosted tree model, the designer works very well. It also helps prevent mistakes like forgetting to USE THE SAME DATA CLEANING on your inference data that you used on your training data. (This is another data science anti-pattern that I have screwed up on in the past.)
Experiments
As I mentioned before, one of the key behaviors of a data scientist is keeping good records of what version of a model was trained on what data with what hyperparameters and what the resulting accuracy metrics were for the testing data. IMO, this is a key differentiator between a professional data scientist, and a citizen/amature data scientist.
There is another really interesting aspect to experiments in Azure ML. An Azure ML experiment can be created, and then ran and re-ran programatically. This opens up a great way to “script” machine learning training. To make this work, the training process needs to be captured in an .py file.
from azureml.core import Experiment, ScriptRunConfig, Environment
from azureml.core.runconfig import DockerConfiguration
from azureml.widgets import RunDetails
# Get the workspace
ws = Workspace.from_config()
# Create a Python environment for the experiment (from a .yml file)
env = Environment.from_conda_specification("experiment_env", "environment.yml")
# Create a script config
script_config = ScriptRunConfig(source_directory=training_folder,
script='diabetes_training.py',
environment=env,
docker_runtime_config=DockerConfiguration(use_docker=True))
# submit the experiment run
experiment_name = 'mslearn-train-diabetes'
experiment = Experiment(workspace=ws, name=experiment_name)
run = experiment.submit(config=script_config)
# Show the running experiment run in the notebook widget
RunDetails(run).show()
# Block until the experiment run has completed
run.wait_for_completion()
Check out the full code here for an example: https://github.com/MicrosoftLearning/DP100/blob/master/03B%20-%20Training%20Models.ipynb
Azure ML allows you to use either Azure’s own experiments framework, or ML Flow. ML Flow is an opensource project developed by Databricks. That said, it seems to me that the Azure framework provides a nicer UI, and more complete functionality. I have attempted to use MLFlow in the past, and it doesn’t do well in corporate environments with complex network topologies. Plus, MLFlow requires you to run an MLFlow server… why do that when Azure essentially offers better functionality without the headache of running a python based server.
Model Training with MASSIVE Data
Training and working with big data is a special challenge in Analytics. There are a number of different approaches including downsampling the data, or trying to scale up the compute. But, what do you do if you come across a dataset that is multiple terabytes or petabytes? An answer to this problem can be found in cluster computing, and Apache Spark is the leading opensource project in this area. Unfortunately, Apache Spark is notoriously difficult to configure and run. The complexities of running computing clusters where worker nodes alll have to be coordinated is a challenging task. AWS attempts to address this problem with ther EMR (Elastic Map Reduce) service… unfortunately that too can be very challenging to get working and very difficult to troubleshoot when it doesn’t. Databricks is a Spark as a Service offering (and company) that makes running Spark very easy. Databricks also offers data storage solutions that work well with their enhanced Spark solution that makes a ton of sense.
Now, the really nice thing about Databricks is that it is actually contained in azure, and accessible from Azure ML Studio…
Azure Databricks is part of the Azure ecosystem, and so it is billed through your Azure account (essentially as a “pay as you go” databricks subscription.) I cannot overstate the value of Databricks when it comes to processing huge data. Historically, Databricks was used for ETL tasks and large scale data engineering. However, it can also be used for machine learning tasks. Databricks has its own ML libraries that take advantage of the underlying Spark infrastructure which makes training models on huge datasets practical. Databricks also works efficiently with the underlying Spark compute clusters (which it gets from Azure compute), and allows you to scale down these clusters when they are not used. But, don’t forget to make sure that option is set because, trust me on this, there is no faster way to create a big compute bill than bring up a gigantic cluster and forget to shut it down over the weekend!
Model Management
Training models is the fun part of data science and analytics, and models that have been trained are assets. A lot of time and effort go into creating models, and that investment is manifest in the trained model artifact. That is why, from a business perspective, it is absolutely imperative that trained models are organized, currated, and the data associated with those models isn’t lost. A huge part of doing data science is running experiments, and seeing if new approaches to solve a data problem result in better results. But, how can you know what a better result is if you cannot put your finger on what your current model’s accuracy was when you trained it? Azure ML does an excellent job of helping not only keep track of models, but providing a way to walk back from a model running in production, to the description of the how the model was trained, to the actual code that trained the model, the data that it was trained on, and the hyperparameters associated with the training. This is all part of Azure model management and azure deplopyments.
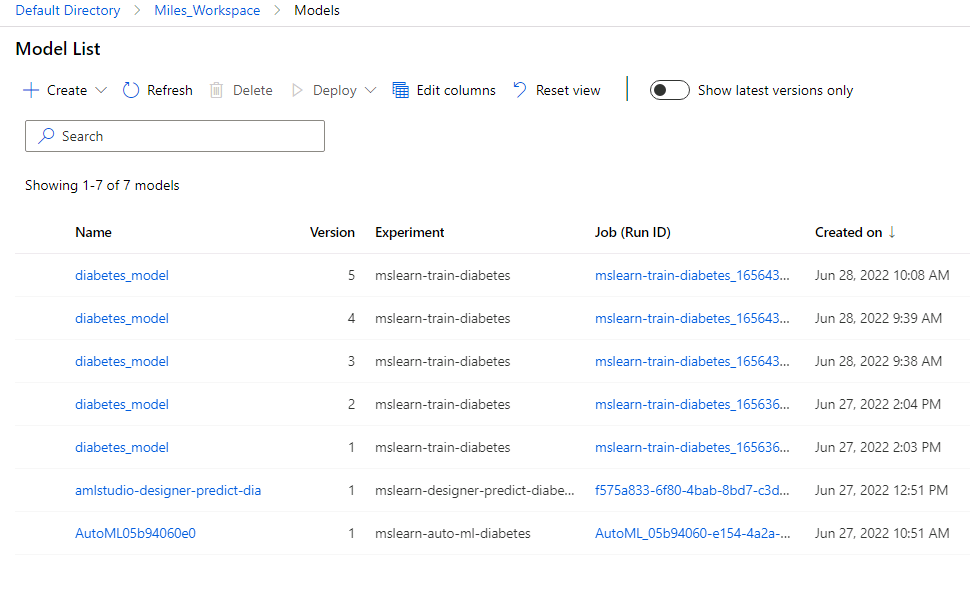
I think that model management is something that is difficult to fully appreciate until you are faced with it in real life. In my early days of messing around with deep learning, I trained a model that had some really good results. At least, I seem to remember that it had really good results. After running the model in production for a few months, someone asked me what the training accuracy was. (Precision, Recall, F1, etc.) I didn’t have that information stored anyway, but I didn’t think it would be a problem. I would just retrain the model. I was shocked when I saw my metrics after re-training. They were nowhere close to what I remembered. I tried and tried, but I could never find the right combination of learning rate, optimizer, etc. that gave me what I needed.
Again, don’t be “ME”! Keep track of your models and you results. This is the path to enlightenment, and Azure ML makes this so easy.
Model Deployment
Once you have a model trained, and the accuracy is acceptable, you are good to go! Except that you are not. You are actually not going anywhere. It is like running 26 miles in a marathon, and not finishing the last 0.2 miles. Deploying the model is how you leverage the investment that you made by collecting and cleaning data, running experiments, and keeping track of results. If you don’t somehow get that model into a workflow within your organization, you have essentially just wasted a TON of effort.
Unfortunately, for most data scientists, that last 0.2 miles of the marathon is a merciless uphill climb. And, for how clever we thought we were with our elastnet feature selection, and our autoregressive integrated moving averages, and our eigenvectors and principal component analysis, we are left staring blankly at a docker build file that just makes no damn sense. DevOPs is a (black) art… at least to a data scientist. And… thank the maker for Azure endpoints. Azure ML provides a very straight forward way to deploy models into production. This can be done on a single compute instance, or into a kubernetes cluster, all automatically. The management tools are all there for monitoring the models. The security protocols have all been worked out so you don’t have to reinvent the wheel and fight tooth and nail with JWTs and OAUTH… unless you want to. And if you do, bless you. The approach also allows you to deploy models not only into production but also on your own workstation via Docker.
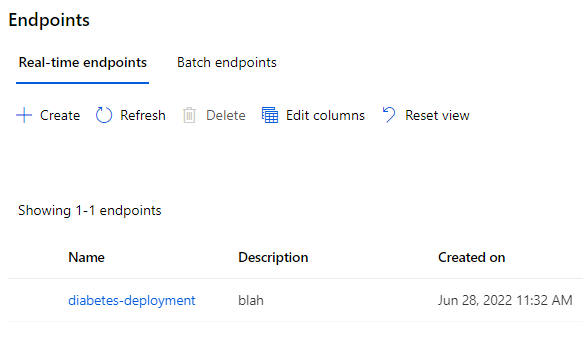
It is important to keep in mind that when you deploy a model, someone is going to call it. And, if they call it, they are going to pass in data and expect a result. That input and output data is another resource. It contains information about your customer and may yield insights. And, so we return back right to where we started…
(And it all comes back to) DATA
When a model is deployed in Azure ML, you have the option to capture insights from the model running in production. Turning on insights will allow you to capture data and metrics for how people are using the endpoints you have created. This is incredibly valuable. The distribution of the OUTPUT of you models is also extremely important. Most models are trained once, and then used over and over. They essentially know their world for a single point in time. However, the universe continues to change. As a result, the longer you run a model in production, the results will start to drift. This means that your model will, over time, become less and less reliable at describing, predicting and prescribing things based on inputs. It is important to watch the distribution of our models outputs in order to know where and how things are changing. Azure ML application insights allows for data capture and monitoring of model inputs and outputs.
A Few Comments About “The Future”
Azure ML Studio isn’t the only way to work with Azure. Microsoft has developed a fully functional SDK that can be used to configure and manage ML data, components, models, experiments, etc. As companies develop more ML models, keeping track of those models will only increase in complexity. Leveraging scripts are a good way to help keep this managable. This is one of the main ideas behind MLOps. I think that the cohesive SDK that Microsoft has developed is particularly valuable in this regard. That said, I appreciate having a GUI available that allows me to focus on solving the problems and not on trying to remember SDK classes and methods. So, there is a balance that needs to be struck. From what I can see, it seems that Microsoft is doing a good job in that regard.
Conclusion
I hope this post has highlights some of the key benefits of running Azure ML. I only touched on a few of them here. I would encourage anyone who hasn’t done so and considers themself a data scientist to check out the Azure ML offering. You can sign up for a free account with $200 credit. The account gives you 30 days to play with Azure ML. The registration does require a credit card, but they will not automatically start charging you when you run out of credits. (At least that is the message you receive when you sign up.)
I think you’ll be impressed by Azure ML. Seriously.
Regards,
Miles