Hadoop and MapReduce - A Test Driven Approach
Introduction

The extreme programming practice of test driven development (TDD) was introduced by Kent Beck in 2003. Since its introduction, TDD has helped to mitigate coding errors in a large number of projects, and is widely considered as a best practice in software development. TDD is focused on catching bugs early, and protecting against regression errors. TDD also helps to ensure that code is written in a modular and organized way.
I have found that blogs and even online tutorials for topics in data science generally don’t mention testing, let alone TDD. I think that is unfortunate. Data science begins with data, both literally and figuratively. If the data is bad, the science doesn’t have much of a chance to be meaningful or insightful. TDD can be a very useful tool in making sure that the data that drives data science is correct and valid.
TDD can very easily be applied to developing Hadoop MapReduce jobs. This blog post will explore one approach to doing just that.
Udacity Hadoop Course
Over my career, I have worked with a number of clustered data stores including SQL Server, MySQL, Oracle, Riak, and Cassandra. I recently decided to explore Hadoop as it is becoming more and more popular as a “Big Data” repository. In order to get a better handle on Hadoop, I enrolled in a (Udacity)[https://www.udacity.com/] course.
The course does a nice job of laying out the Hadoop ecosystem, and highlighting how to use map reduce jobs with streaming. The course also mentions that you can test Hadoop mapreduce jobs in a Unix/Linux bash shell by using streams and pipes. Unfortunately, the tests that are mentioned are all run from the command line and use pipes and “sort” as a way to test. This is testing, but it is a long way from automated. It also only offers a very high level blackbox test. While TDD takes a little time to get set up, the benefits that it provides are substantial. I won’t go into all of the (mostly common sense) reasons that developers should leverage TDD. I will, however, simply point to the book. Available on Amazon:

Mapreduce Jobs as Python Scripts
One of the nice things about Hadoop map reduce jobs is that you can write them in a variety of languages. The Udacity course uses python, and so will I. I think that python not only serves as an easy to read and write language, it also has some very nice testing features that we will see in a moment.
In the Udacity course, one of the problems that students need to solve is to write a mapreduce job to query a standard apache web server log. To do this with Hadoop mapreduce, you need to write two small programs, a mapper and reducer. A mapper is used to parse the lines of the apache log, and is distributed out across the nodes of the Hadoop cluster when it is run. That is where we will begin with our tests. Later, we will create a reducer that will summarize the data that is extracted by the mapper job.
First, however, let’s set up a directory structure for our tests and code.
[training@localhost hadoop_tdd]$ tree
.
├── README.md
├── apache_parser.py
├── data
│ └── access_log_test_fixture
└── test
└── apache_parser_test.py
Note: I have made this code available online in my hadoop_tdd git repo.
Eventually, there will be more code in here. I am, however, going to drive the creation of that code based on tests. I start by creating my first test file: apache_parser_test.py, This file will test a parser that I am planning to write, and will specifically test a “parse()” method that will be provided by the apache_parser.py class.
import apache_parser
import unittest
class TestApacheParser(unittest.TestCase):
def test_parse(self):
parser = apache_parser.apache_parser()
result = parser.parse("stuff")
self.assertTrue(result is not None)
if __name__ == '__main__':
unittest.main()
You may notice that I am actually doing object oriented python. The reason for this is that by using objects and making the code modular, I will be able to test individual small pieces of functionality (like the parser test above) in isolation. This is a key aspect of TDD.
To get this code to run, I will need to create the parse() method in the apache_parser.py file like so:
class apache_parser:
def parse(self, line):
return None
When I execute this test, it fails.
/usr/bin/python "/Applications/PyCharm CE.app/Contents/helpers/pycharm/_jb_unittest_runner.py" --path /Users/milesporter/data-science/hadoop_tdd/test/apache_parser_test.py
Testing started at 7:32 AM ...
Ran 1 test in 0.001s
FAILED (failures=1)
...
AssertionError: False is not true
Process finished with exit code 1
That is what we expect when doing TDD. We start not only with a test, but with a failing test. Then, we make that test pass. Next, we break things again by putting in a test that isn’t satisfied yet. Then we write the code to make that test pass… and so on, and so on…
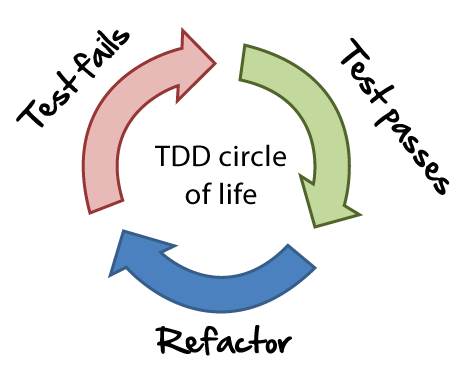
First meaningful test
The first thing that I want my code to do is to log an error message and return None if a line of apache log stuff cannot be parsed. Here is a test that does that:
from apache_parser import apache_parser as Parser
import unittest
import mock
class TestApacheParser(unittest.TestCase):
@mock.patch('apache_parser.logging')
def test_parse_invalid_line(self, my_mock):
parser = Parser()
result = parser.parse("stuff")
self.assertTrue(my_mock.log.called, "Failed to log an error message.")
self.assertTrue(result is None)
if __name__ == '__main__':
unittest.main()
In this code, I am asserting that a logging statement gets called and that my call to my parsing class returned None. Note the annotation on the test method:
...
@mock.patch('apache_parser.logging')
def test_parse_invalid_line(self, my_mock):
...
Here I am using mocking for Python 2.X. Why, you may ask, in the heck am I using python 2.X. Here is the full deal… This is all coming from trying to get the Hadoop Udacity training done. The Hadoop Udacity training comes with a virtual box image that has the Cloudera Hadoop distribution installed on CentOS 6.9. Unfortunately, CentOS version 6 depends on python 2.6. I could install other python version on the virtual machine per this blog post but I decided just to keep things simple and stay with 2.6.
Here are some additional tests that we can write:
from apache_parser import apache_parser as Parser
import unittest
import mock
class apache_parser_test(unittest.TestCase):
@mock.patch('apache_parser.logging')
def test_parse_invalid_line(self, my_mock):
parser = Parser()
result = parser.parse("stuff")
self.assertTrue(my_mock.log.called, "Failed to log an error message.")
self.assertTrue(result is None)
@mock.patch('apache_parser.logging')
def test_valid_line(self, my_mock):
parser = Parser()
result = parser.parse('10.223.157.186 - - [15/Jul/2009:15:50:35 -0700] "GET /assets/js/lowpro.js HTTP/1.1" 200 10469')
self.assertTrue(len(result) == 7)
self.assertTrue(result["host"] == '10.223.157.186')
self.assertTrue(result["user"] == '-')
self.assertTrue(result["client"] == '-')
self.assertTrue(result["time"] == '15/Jul/2009:15:50:35 -0700')
self.assertTrue(result["request"] == 'GET /assets/js/lowpro.js HTTP/1.1')
self.assertTrue(result["status"] == '200')
self.assertTrue(result["size"] == '10469')
self.assertFalse(my_mock.log.called, "Logged error when none should have been logged.")
Finally, here is the code that satisfies my test cases above:
import logging
import re
class apache_parser:
def parse(self, line):
try:
p = re.compile(
'([^ ]*) ([^ ]*) ([^ ]*) \[([^]]*)\] "([^"]*)" ([^ ]*) ([^ ]*)'
)
m = p.match(line)
host, user, client, server_time, request, status, size = m.groups()
result = {'host': host, 'user': user, 'client': client, 'time': server_time, 'request': request, 'status': status, 'size': size}
return result
except Exception:
logging.log(logging.WARNING, "Error parsing line.")
return None
Let’s now continue with a couple tests for our mapper and our reducer.
#Testing mappers and reducers
Now that we have a nice little tool for parsing out the lines of the apache log file, writing the parser becomes fairly simple. All we need to do is write a python script that takes a line in standard input, then parses the line and only returns those items that we care about. In this case of gathering page counts in the log, all we want is a timestamp, and the requested page.
Before we I implement that, we need to write a test! Since this is going to be running a level above my previous code, I am going to create a new test class…
class ApacheLogMapperTest(unittest.TestCase):
@mock.patch('apache_parser.apache_parser')
def test_mapper_can_parse_from_standard_in(self, my_mock):
mapper = Mapper()
mapper.parser = my_mock
mapper.sysin = open('../data/access_log_test_fixture','r')
mapper.parse()
self.assertTrue(my_mock.parse.called, "Failed to call the parser!")
@mock.patch('sys.stdout')
def test_mapper_can_save_data(self, my_mock):
mapper = Mapper()
mapper.sysin = open('../data/access_log_test_fixture', 'r')
mapper.sysout = my_mock
mapper.parse()
self.assertTrue(my_mock.write.called, "Failed to output data message.")
This file contains 2 test cases. The first one simply confirms that when I run the mapper file, my parser gets run. I could (and probably) should be more thorough here and actually assert that it gets called the correct number of times but for now, this is good enough. At this point I DON’T TEST WHAT THE PARSER DOES. I have already done that. If I duplicate the test here, and things break, I will just end up having more tests to fix.
The second test asserts that when I parse the input stream, that data actually gets written to standard out.
Here is the code that satisfies that test:
#!/usr/bin/python
import logging
import sys
sys.path.append('./')
from apache_parser import apache_parser as Parser
logging.basicConfig(filename='mapper.log')
class ApacheLogMapper():
sysin = sys.stdin
sysout = sys.stdout
parser = Parser()
def save_data(self, request, host):
self.sysout.write("{0}\t{1}\n".format(request.split()[1], host))
self.sysout.flush()
def parse(self):
print("Got to here!")
logging.debug("Starting mapper job")
try:
for line in self.sysin:
data = self.parser.parse(line)
if data is not None:
self.save_data(data["request"], data["time"])
except Exception as ex:
logging.error("An error has occurred:\n{0}\n".format(ex.message))
finally:
logging.debug("Mapping complete. Closing local mapper log file.")
#Do the work
if __name__ == "__main__":
mapper = ApacheLogMapper()
mapper.parse()
There a couple things here to note. First, the above python file contains a class, but it can be executed as a script. This is important for how Hadoop interacts with classes. Also, note the following line:
sys.path.append('./')
This little fella was a pain to figure out. Hadoop has an interesting way of dealing with scripts and streaming. The line above makes it possible for Hadoop to find the apache_parser module. With out this line, my tests would run just fine locally, but fail on the server because the server was unable to locate that class. I was able to find this answer on stack overflow.
Now, it is time for a reality check. I will use the trick that the Udacity course recommends for testing this stuff on the command line:
$ cat ./data/access_log_test_fixture| python apache_log_mapper.py
...
/assets/swf/media-player.swf 28/Jul/2009:06:56:13 -0700
/assets/flv/dummy/home-media-block/district-13.flv 28/Jul/2009:06:56:13 -0700
/contact-us 28/Jul/2009:06:56:28 -0700
/contact-us/ 28/Jul/2009:06:56:28 -0700
/assets/js/lightbox.js 28/Jul/2009:06:56:28 -0700
/assets/css/reset.css 28/Jul/2009:06:56:28 -0700
/assets/css/960.css 28/Jul/2009:06:56:28 -0700
/assets/css/the-associates.css 28/Jul/2009:06:56:28 -0700
/assets/js/lowpro.js 28/Jul/2009:06:56:28 -0700
/assets/js/the-associates.js 28/Jul/2009:06:56:28 -0700
/assets/img/home-logo.png 28/Jul/2009:06:56:30 -0700
/assets/img/search-button.gif 28/Jul/2009:06:56:30 -0700
/assets/img/closelabel.gif 28/Jul/2009:06:56:30 -0700
/assets/img/loading.gif 28/Jul/2009:06:56:30 -0700
/ 28/Jul/2009:06:56:38 -0700
/assets/css/reset.css 28/Jul/2009:06:56:39 -0700
/assets/css/the-associates.css 28/Jul/2009:06:56:39 -0700
/assets/css/960.css 28/Jul/2009:06:56:39 -0700
/assets/js/lowpro.js 28/Jul/2009:06:56:39 -0700
/assets/js/the-associates.js 28/Jul/2009:06:56:39 -0700
/assets/js/lightbox.js 28/Jul/2009:06:56:39 -0700
/assets/img/dummy/secondary-news-4.jpg 28/Jul/2009:06:56:39 -0700
/assets/img/search-button.gif 28/Jul/2009:06:56:39 -0700
/assets/img/dummy/primary-news-2.jpg 28/Jul/2009:06:56:39 -0700
/assets/img/dummy/secondary-news-1.jpg 28/Jul/2009:06:56:39 -0700
/assets/img/home-logo.png 28/Jul/2009:06:56:39 -0700
...
BOOM! It worked. Which actually should not be a surprise, since we did test all the individual parts of our mapper. Now all I have to do is implement a reducer and I should be in business. The reducer simply adds up all the counts for each different page. Here is where I we need to be considerate about what we are doing. A very basic way to solve this problem might be to write a separate class that holds counts of all the separate keys. You could even do this with a basic dictionary that contains the name of the page, and the counts for that page. However, I believe that would be antithetical to what we are trying to do with a reducer. One of the key features of the mappers is that they not only return the items that we want, they also return them pre-sorted. Keeping track of all the pages is going to take a ridiculous amount of memory.
To approach this in a more efficient way, we can leverage the fact that the data is pre-short as a result of the call to the mapper. However, without storing the entire list of keys, being able to test that we get accurate counts is a little tricky. Here I compromised a bit in the design of my reducer. The reducer method takes a parameter that contain the value of a key to search for. If that key is found in the counts, its value is returned for testing. In production, we don’t need to search for specific keys, and so we just pass in a null. Here is a test that shows what I am trying to do…
def test_reducer_counts_right(self):
reducer = Reducer()
reducer.sysin = open('../data/reducer_fixture', 'r')
count = reducer.reduce('the-associates.js')
self.assertTrue(count == 24)
And here is the reducer that satisfies the above test.
#!/usr/bin/python
import sys
class ApacheLogReducer():
sysin = sys.stdin
sysout = sys.stdout
def save_data(self, page, count):
self.sysout.write("{0}\t{1}\n".format(page, count))
self.sysout.flush
def reduce(self, key):
result = None
page = ""
currentPage = None
count = 0
for line in self.sysin:
fields = line.split()
ip = fields[-1]
page = fields[0]
if page != currentPage:
if count > 0:
self.save_data(currentPage, count)
if key is not None and key in currentPage:
result = count
currentPage = page
count = 1
else:
count = count + 1
# Don't forget the last page.
self.save_data(page, count)
return result
if __name__ == "__main__":
reducer = ApacheLogReducer()
reducer.reduce(None)
A few comments
In order to get the code to actually run in Hadoop, I need to make sure that I pay special attention to a few things:
-
As mentioned above, It is important to use “sys.path.append(‘./’)” to ensure that any lib/utility classes you create get imported when the code is running in Hadoop.
-
If things go wrong in Hadoop, there is a log file that gets stored in the output directory. (Remember that you can use “hadoop fs -ls” to see the contents of the output directory.
-
Writing the code in classes does take on a slight performance hit. However I believe that this is justified by being able to know that your mappers and reducers are doing what you want them to do.
-
The Cloudera Hadoop virtualbox runs on CentOS 6.9. The default version of python for that distribution of linux is 2.6… don’t change it. The CentOS 6.9 depends on linux 2.6… despite the fact that it is several version out of date.
Conclusion
So, there you have it. In case you are wondering, the correct answer to the Udacity Hadoop Introduction Course Quiz #6 question is:
2456