Reflections on Halicon 2017
Introduction

I had the pleasure of attending Halicon2017 on October 6th. The conference, hosted by Optum/UnitedHealth Group and Minne-Analytics was held at the beautiful UHG conference center in Eden Prairie, MN. It was an interesting opportunity to meet some old folks and new friends, hand out business cards and find out what is happening in data analytics and data science in the health care sector. Below are some of my impressions for the sessions that I attended.
Natural Networks: A New Way to Design and Manage Provider Networks.
Sanji Fernando
Vice President, OptumLabs Center for Applied Data Science, OptumLabs.
In his session on Natural Networks, Sanji Fernando of UHG talked a bit about OptumLabs, and the work that his team has been doing on “Natural Networks.” Essentially, a “Natural Network” can be thought of as a hypergraph that consists of nodes that represent health care providers. The nodes are connected with edges that represent shared patients that visit the linked providers. The graph is built from data that UHG has access to as a “Qualified Entity” from the Centers for Medicare and Medicaid Services. The data used to build the graph is is anonymized and de-identified. The difference between the two, I learned in the session, is that anonymized data may still contain information that could be used to identify the individual in question. An example might be a geolocation and a timestamp. This data could be used in conjunction with social media posts or checkins to identify specific individuals.
The goal of the natural networks, from a business perspective, is to allow employers the ability to “fine tune” their provider networks when they create their health plans. This might allow employers to identify networks of providers that provide better outcomes at lower cost.
The main question that I had about the natural networks relates to how the networks change over time. This got me thinking about how to use machine learning techniques to model the change in sub-networks of the hypergraph over time. I am still kicking this around in my head.
The main technologies that UHG is using for constructing the graphs is NeoForJ and some visualization libraries including the JavaScript D3 library.
I enjoyed this presentation, and feel that it was probably the second best one that I saw at the conference.
Never Trust the RoboDocs! (Or Should You?)
Ingo Mierswa, PhD
CEO RapidMiner
The next session that I attended was given by Dr. Ingo Mierswa, the CEO of RapidMiner. The presentation focused on a number of different topics all centered around the idea of trust.
“…But while healthcare is all about trust, machine learning models often are black boxes – which makes it inherently difficult to trust them.”
The session focused on some specific techniques around building trust in data. I was particularly impressed with Dr. Mierswa’s discussion on testing. His talk focused a great deal on looking at preparing data and making sure that steps are taken to ensure that the data used to train machine learning models has been thoroughly tested. I agree with that, but would go one step further and suggest that the CODE that does the data prep should be TEST DRIVEN, just as the code that builds and trains the models should be. I feel that testing in general is overlooked in data science.
Another point that Dr. Mierswa mentioned was making sure that training and validation data are separate. The term he used for this was cross validation. I get the impression that some people don’t do a good job of separating training and validation data when it comes to modeling. This is a bit strange to me because many frameworks, including sklearn and Keras, make separating data sets into training and validation subsets very easy.
The last point that Dr. Mierswa made was to “own your results”. In my experience, this is a well known and common practice in application, API and microservice development. Susan Fowler has written about this idea on her blog.
Overall, this was a good session, despite some distracting environmental things like flickering overhead lights (which I hate.) Dr. Mierswa is a very dynamic, interesting and funny speaker. I suggest that you attend any of his sessions if you get the chance.
Analyzing the Patient Care Continuum: 99M patients, Hadoop and Spotfire
Shihe Ma, MS, MBA
Medtronic
I had intended to see the session “Network Analytics for Narcotic Safety Initiatives” by Prasanna Desikan. Despite the fact that I arrived at the room about 5 minutes early, there were no seats left. Rather than sit on the floor, I opted to go to the session on Hadoop and Spotfire.
I was a bit disappointed with this session. While the data for the session was stored in Hadoop, the presenter admitted that he did nothing with Hadoop. All of the Hadoop configuration and management was taken care of by the IT group at Medtronic. None of the Hadoop configuration information was covered in the session. The data access work that he did was done with Apache Impalla, which provided access to the Hadoop data through SQL.
Tibco Spotfire is a visualization tool for building dashboards, not all that unlike Tableau. This site contains an analysis of the two tools. I have had some exposure to Tableau, but this was my first look at Spotfire. It seemed like a fairly nice tool, but was a very “point and click” approach to developing dashboards and reports. The presenter mentioned that the dashboards that they build, which contain data on spinal patients, are primarily used by marketing.
The presentation finished about 15 minutes early. I don’t think that the presentation was necessarily bad. That said, I didn’t learn much. I hope that the Halicon folks take into consideration the sizes of the rooms next year. In general, the rooms felt small.
Oh… and the bathrooms.
THEY NEED MORE BATHROOMS!
Lunch
I had a nice discussion over lunch with several data scientists at UHG/Optum as well as another independent consultant and a student at the U of M. I was amazed to learn that the U is still teaching Visual Basic. That is just sad.
It was interesting to hear and compare what current employees think of UHG and Optum versus my experiences working there about 15 years ago. Some of the people that I worked with back then are still at UHG, and some are even in fairly high and even “C-level” senior management positions. My impressions of the old UHG was that it was very political, and that a great deal of pressure was applied to business units to keep up the year over year double-digit growth the company has experienced. It sounds like many things at UHG have gotten better.
Hypergraph in Precision Medicine, Beyond Watson.
Scott Jenkins, PhD.
CEO, Advanced Molecular Services Group (SFO)
The next session was given by Dr. Scott Jenkins of Advanced Molecular Services Group. The focus of his presentation was on the use of Hypergraphs in precision medicine. This talk focused on some of the same technology as the first session on “Natural Networks”, and some of the same tools including Neo4J were mentioned.
I found this presentation overly full of buzzwords. Dr. Jenkins mentioned Bayesian techniques, but I struggled to see exactly where they were being applied. He moved pretty quickly and was fairly thin when it came to details of exactly what he was talking about.
One interesting slide in the presentation showed a hypergraph representation of proteins. I think that is what the graph was showing, anyway. I left the presentation thinking that the talk was either way over my head, or overly vague… Perhaps it was both.
Applying Blockchain to Healthcare
Mike Jacobs
Distinguished Engineer, UnitedHealth Group/Optum
The mid-afternoon session that I attend was on using blockchain in health care. I had come across blockchain in the past, but it was good to have an overview of the technology again. Mike Jacobs did an excellent job of explaining the technology. I particularly appreciated his approach to looking at blockchain as it has evolved over time, and separating it from the cryptocurrency Bitcoin. Bitcoin uses blockchain, but it is a common misconception to say that the two are the same thing. Mike did a good job of explaining how bitcoin is an implementation of the combination of cryptocurrency and blockchain.
As part of his presentation, Mike offered a chart that shows some of the potential applications of blockchain in health care and beyond. (Please excuse the top of the head of the individual in front of me.)
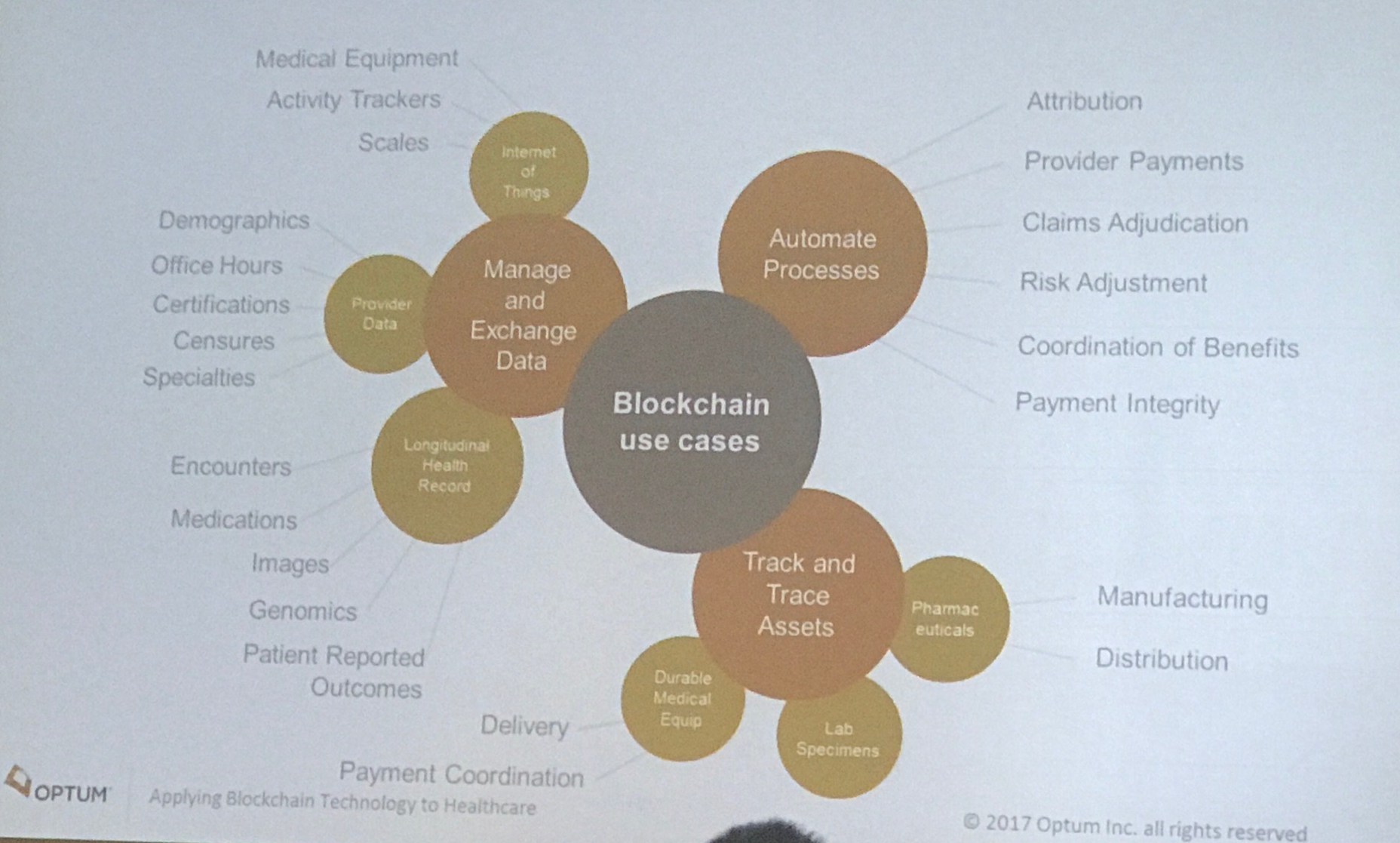 (Copyright Optum, Inc. 2017. Used by permission.)
(Copyright Optum, Inc. 2017. Used by permission.)
In his discussion, I appreciated the fact that Mike mentioned some of the potential issues with blockchain including the 51% Attack vulnerability. I often hear speakers talk only about the benefits and potential upsides of a specific technology they are presenting. It was refreshing to have a rational and critical look at blockchain.
Mike’s team has pulled together a nice little tool to help people evaluate the viability of using blockchain for their particular business case or idea. It is publicly available here:
Two Use-cases and a Summary: AI in Health for Diabetes and Communicable Disease
Karen Hayrapetyan
Senior Data Scientist, H2O.ai
Sanjay Joshi
CTO, Healthcare and Life Sciences, H2O.ai
The last presentation of the day that I attended was Two Use-cases and a Summary: AI in Health for Diabetes and Communicable Disease. This was, by far, the best presentation that I attended at the conference. The first half of the presentation was given by Dr. Karen Hayrapetyan. The team that Dr Hayrapetyan is a part of is largely responsible for the GPU portion of XGBoost. The talk started with a brief discussion of taking data, focusing on quality and QA to build a modeling table, then building a model and validating it. Karen echoed the comments that were made by Dr. Mierswa regarding the importance of using clearly separated training and validation data.
The second use case the Dr. Hayrapetyan presented on was focused on time series data. The tools that his team used to explore this data set focused on random forest and gradient boosting algorithms. One question that I had regarding the tools that they used was why they didn’t explore using LSTM neural networks. His answer was that the case studies were taken from work that they did for clients, and that the clients had specifically requested that the work NOT include neural networks or deep learning techniques. I am not sure of the reason for this, but suspect that it might relate to the fact that some people and institutions don’t like using “black box” techniques. Again, this is something that Dr. Mierswa spoke about in his talk. I personally feel that using artifacts from training neural networks (specifically learning curves, model loss) can show that neural network models do actually converge to a solution. Regardless, the ideas of preprocessing and validating data can be applied to ANNs as well as other modeling techniques.
The second half of the presentation was given by Dr. Joshi. His presentation was a bit more high-level and covered a variety of subjects. That said, I felt that his information was well researched and well articulated. I was fascinated to hear him talk about things like “the microbiome is the largest endocrine organ in the human body” and that “onions have more meaningful genes than humans.” The last statement comes from this article in Harvard Gazette.
One of the main points that Dr. Joshi was making was simply that there is so much data available regarding healthcare, it is not humanly possible to examine it without using tools like machine learning and AI.
Conclusion.
I wasn’t quite sure what to expect from the Halicon conference, but I can say that I am quite happy that I attended. I found the conference to be fairly well organized. Despite some issues regarding not having enough room, the conference facility was fairly comfortable. The people in attendance were clearly knowledgable and the conference was free from being overpowered by recruiters and vendors. I look forward to the opportunity to attend the conference next year as well.
Thanks for taking the time to read this post, and check back soon for more blog posts regarding data science and machine learning. In the meantime, if you are looking for additional people to help out with your machine learning and application development projects, please don’t hesitate to contact me at the address below.
-Miles Porter