Speech Recognition using MFCC and HMM
Introduction
My avid blog readers (that’s you, Dad) are undoubtedly aware that I have spent the last couple months on sabbatical doing research into various topics in data science and machine learning. I have also done more than one load of laundry. I don’t mind doing laundry with the notable exception of folding fitted sheets. A few weeks back, I made a commitment to become proficient in that horrible task. My thinking was this: If, at the end of my sabbatical, the only thing that I learned was how become better at the awful task of folding fitted sheets, my time will have been well spent.
Today is “sheets day” in our house. Sheets day is on Wednesday, and it is the day that we wash and change the sheets on our beds. Today, I am happy to announce that I finally have this down thanks to Martha Stewart and YouTube. Say what you will, haters. But before you do, I ask you…
Can you do this?

I didn’t think so. :)
Correctly folding a fitted sheet is just a sequence of steps. (Check out Martha’s video.) We can think of this sequence of steps (and the probability of making the correct next move at each step) as a Markov Chain. If we combined Markov Chains with a time frequency domain tool called Mel Frequency Cepstral Coefficients, and throw in a little machine learning along the way, we have the necessary tools to create a speech recognizer. (See my blog post on Fourier transforms for more info about analyzing time frequency domain of audio signals.)
Note: This blog post will follow some of the work done in Python Machine Learning Cookbook. The code I wrote for this post is available in my speech recognition repo on GitHub.
Mel Frequency Cepstral Coefficients - MFCC
The first thing that a speech recognizer needs to do is convert audio information into some type of numerical data. In my post on Fourier transforms, I wrote about one way to do that. For speech recognition, just having the Fourier transform doesn’t go far enough. This post goes into some detail on how MFCCs can be used to extract numerical features from audio data. The process involves applying a set of filters called Mel Filters on slices of the overall file, and from there getting to a set of numbers that represent the clip. Fortunately, the python_speech_features library takes care of the details in implementing the MFCC. Here is an example…
from python_speech_features import mfcc
from python_speech_features import logfbank
import scipy.io.wavfile as wav
import matplotlib.pyplot as plt
#Read in the audio file
(rate,sig) = wav.read("./data/miles/one.wav")
# Calculate the mfcc features based on the file data
mfcc_feat = mfcc(sig, rate, nfft=1200)
# Calculate the filterbank from the audio file
fbank_feat = logfbank(sig, rate, nfft=1200)
#Print the result
print(fbank_feat[1:3, :])
filterbank_features = fbank_feat.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()
The output of this program shows my “voice signature” speaking the word “one.”
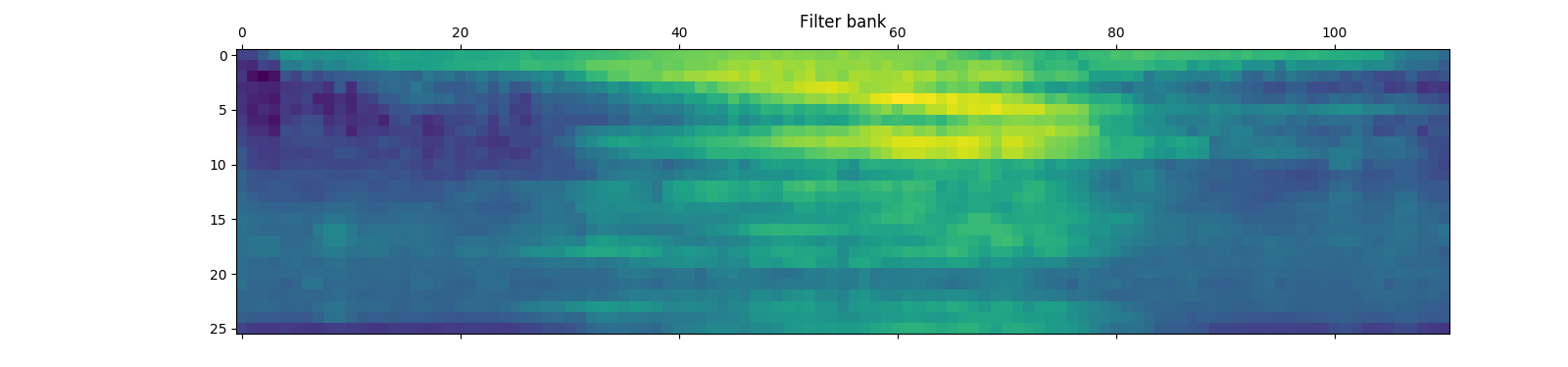
An important thing to understand here is that the mfcc_feat listed above is giving us 2 dimensional ndarray:
fbank_feat.shape
Out[4]: (111, 26)
This is crucially important. The 111 rows in this array are the features for MFCC-ized generalized samples within the audio file. Think of it like this… we split the file up into a bunch of time chunks. From there we compute the frequency domain and use the MFCC process to pull out only the most important, relevant frequencies that we hear FOR EACH CHUNK IN THE FILE. We’ve decomposed the audio file into a series of snapshots of metadata that we can now consider a sequence. The next step in this process will be to use Hidden Markov Chains to map these sequences.
Hidden Markov Models - HMM
Andrey Andreyevich Markov, a Russian mathematician from the late 19th century made several important contributions to the study of statistics and probability. In the process, he worked on the study of sequences of dependent variables, which are now called “Markov Chains”.(1)
Victor Powell and Lewis Lehe have written an excellent blog post on Markov Chains. The post includes a nice visualizer that gives a very good sense of how Markov Chains work. A Markov chain where the probabilities are well known at each state is sometimes called a Markov model.
Hidden Markov Models are an extension of Markov models. Hidden Markov models, are used when the state of the data at any point in the sequence is not known, but the outcome of that state is known. For a great visual representation of this idea check out this YouTube video by Jeffery Miller of Brown University.
In his book Python Machine Learning Cookbook, Prakeet Joshi ties HMMs into what we need to do for speech recognition:
An HMM is a model that represents probability distributions over sequences of observations. We assume that the outputs are generated by hidden states. So, our goal is to find these hidden states so that we can model the signal.
In order to do that, Joshi has written a class that takes care of the above task:
from hmmlearn import hmm
import numpy as np
# Class to handle all HMM related processing
class HMMTrainer(object):
def __init__(self, model_name='GaussianHMM', n_components=4, cov_type='diag', n_iter=1000):
self.model_name = model_name
self.n_components = n_components
self.cov_type = cov_type
self.n_iter = n_iter
self.models = []
if self.model_name == 'GaussianHMM':
self.model = hmm.GaussianHMM(n_components=self.n_components,
covariance_type=self.cov_type, n_iter=self.n_iter)
else:
raise TypeError('Invalid model type')
def train(self, X):
np.seterr(all='ignore')
self.models.append(self.model.fit(X))
# Run the model on input data
def get_score(self, input_data):
return self.model.score(input_data)
Some Data
Now that we have a method for converting the audio information into useful sequences of data, and a technique for modeling those sequences, lets take a step back and think about what we want to do here.
The goal of this blog post is to come up with a speech recognition system that will recognize spoken digits from 0-9. In order to do that, we need some data that can be used to train our model. I originally tried to create my own data. I recorded 10 samples of me speaking the digits 0-9 each. I then created a testing set of separate files. Unfortunately, I was only able to get the model to accurately analyze the audio files 60%-70% of the time.
In a second attempt, I used the data from this GIT repo which includes the digits 0-9, but includes recordings from 2 different speakers, and 50 recordings each for a total training set of 1000 items. I then selected one recording of each digit at random and moved them from the training set to a testing set.
Next, I used the HMM framework, as wrapped by Joshi, to get the best guess as to the numerical digit that corresponds to each of the testing files.
I am happy to say that using this data set resulted in 100% accuracy.
Filename: 0_jackson_0.wav, Digit: 0
Filename: 1_nicolas_1.wav, Digit: 1
Filename: 2_jackson_17.wav, Digit: 2
Filename: 3_nicolas_8.wav, Digit: 3
Filename: 4_jackson_15.wav, Digit: 4
Filename: 5_nicolas_15.wav, Digit: 5
Filename: 6_jackson_22.wav, Digit: 6
Filename: 7_nicolas_8.wav, Digit: 7
Filename: 8_jackson_7.wav, Digit: 8
Filename: 9_nicolas_4.wav, Digit: 9
Note: In the above, the first character in the “filename” is the actual spoken digit. The “Digit: “ is the model’s guess.
Some Code
As I mentioned previously, the code for this blog post was largely influenced by Prakeet Joshi’s book. I found his code difficult to read and so I restructured it to be more modular. I also changed the way that the data is organized. Rather than relying on a directory structure to identify the names of the training data, I adopted a coding convention used in the “free-spoken-digit-dataset”. I am still not 100% satisfied with the state of the code, but I think that it is much more modular and self-explanatory than it was before. I also included some tests, though not nearly enough. I am still amazed at how many data science blog post that I have come across that have absolutely no tests. My code, frankly, is not much better. I did, however put a framework in place for additional tests.
Also, I had to add the following line to Joshi’s “HMMTrainer” class init method…
warnings.filterwarnings("ignore", category=DeprecationWarning)
Without that line, the program spews thousands of deprecation warnings like so:
DeprecationWarning: Function log_multivariate_normal_density is deprecated; The function log_multivariate_normal_density is deprecated in 0.18 and will be removed in 0.20.
Conclusions
With the advent of Siri and Alexa, the topic of speech recognition is receiving renewed interest. Mel Frequency Cepstral Coefficients and Hidden Markov Models are tools that can be used for speech recognition tasks.
My initial attempts at using the MFCC/HMM approach was not very successful. I believe that this may have been due to the small number of test data files and the fact that I was recording the files on my Mac.
The following graph shows the filter bank for a sample from the “free-spoken-digit-dataset”. The one below it is from my own voice. Both graphs are for the spoken digit “one”.
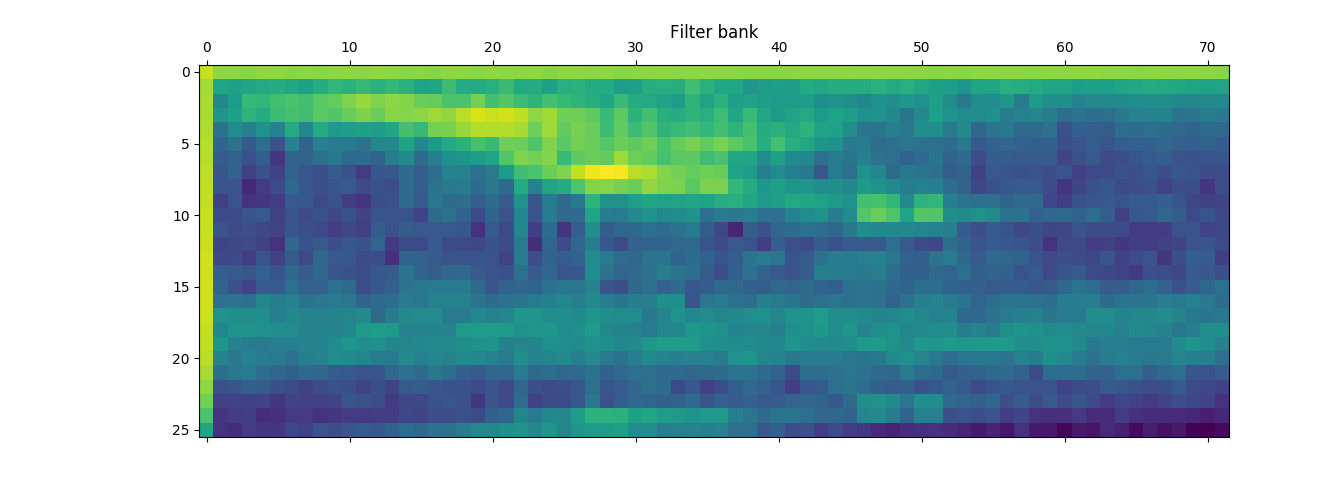
In the above, the first file appears to have more blue areas, and the second more yellow. (The graphs are “heat maps” with yellow indicating higher energy at a given frequency and time.) That would seem to indicate that there is more “color” associated with that recording. I think that it is also interesting to note that different words, like “pineapple” have much more interesting “footprints”. That should not be to surprising simply because the word “Pineapple” is longer and it makes sense that it would have a broader range of frequencies than the word “one.”
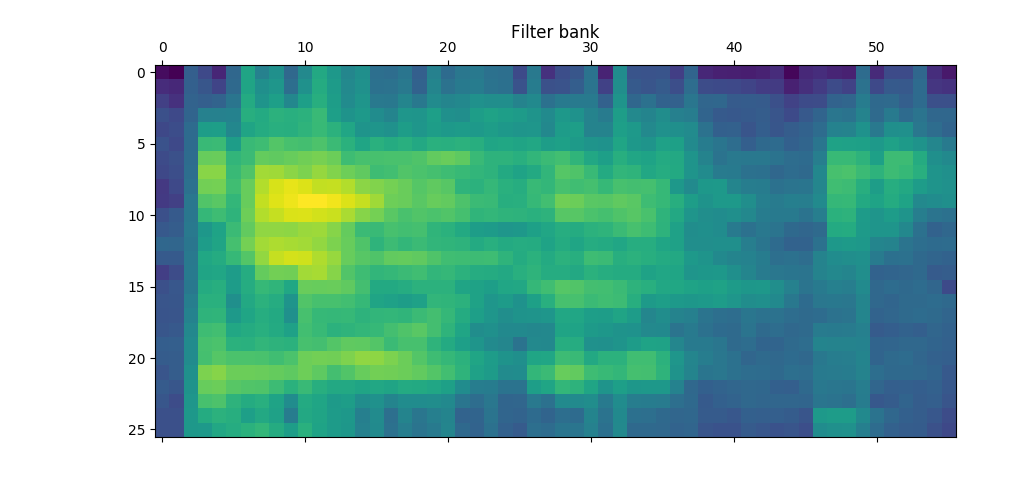
Although a main point of using MFCCs is to reduce audio data down to frequencies that make sense with human hearing, I suspect that having clean, consistent training data is important for the models to work well.
Another unfortunate result of the graphs above is that my wife now has visual evidence that I do, in fact, mumble.
I hope you have enjoyed this post. If you have comments or questions, please feel free to reach out.
Miles.
References
-
Encyclopedia Britannica Online. https://www.britannica.com/biography/Andrey-Andreyevich-Markov
-
Joshi, Prakeet. Python Machine Learning Cookbook. ISBN: 1786464470, 9781786464477.
-
YouTube video by Jeffery Miller of Brown University on Hidden Markov Models.