Python Pandas and Data Frames
Python Pandas and Data Frames
I admit it. Up to now, I have typically used MS Excel when working with data - with some frustration, I might add.
Turns out, there are a number of tools that making working with data much, MUCH easier. Pandas is a python package that provides some very useful features for working with tabular data sets. It also provides convienent tools for working with data files (.csv, etc.)
This blog post will focus on using pandas’ DataFrame class for working with tabular data sets. So, let’s get started:
Series
Before I get to dataframes, it probably makes sense to describe how Series work. A Series stores, well, a series of elements. In this respect, it is very similar to list (or array.)
>>> from pandas import DataFrame, Series >>> >>> age = Series([52,56,49,17,14,14,12,12,12]) >>> gender = Series(["F","M","M","F","F","M","F","M","M"]) >>> rank = Series([20,18,14,0,15,14,14,11,4])
However, unlike arrays, Series offers some out of the box features like mean, median and standard deviation. For example:
>>> from pandas import DataFrame, Series >>> age = Series([52,56,49,17,14,14,12,12,12]) >>> age.mean() 26.444444444444443 >>> age.median() 14.0 >>> age.std() 19.55831735548275
Series also have the apply operator. That allows us to perform a lambda function on each element of the Series. For example:
>>> dx = age.apply(lambda x: x**2) >>> print(dx) 0 2704 1 3136 2 2401 3 289 4 196 5 196 6 144 7 144 8 144 dtype: int64
There are many other methods available for use with Series. For a complete list, refer to the docs at
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.html
Dataframes
DataFrames are
…a Two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns). Arithmetic operations align on both row and column labels. Can be thought of as a dict-like container for Series objects.
… which just sounds cool!
Much in the way that Series provides methods that are not available on a basic python list, DataFrame provides similar methods for dealing with tabular data. As an example, I have created a very basic dataframe below that contains basic demographic information for the Karate Class that I attended last night…
>>> from pandas import DataFrame, Series
>>>
>>> age = Series([52,56,49,17,14,14,12,12,12])
>>> gender = Series(["F","M","M","F","F","M","F","M","M"])
>>> rank = Series([20,18,14,0,15,14,14,11,4])
>>> karate = DataFrame({"age":age,"gender":gender,"rank":rank})
>>> print(karate)
age gender rank
0 52 F 20
1 56 M 18
2 49 M 14
3 17 F 0
4 14 F 15
5 14 M 14
6 12 F 14
7 12 M 11
8 12 M 4
As you can see from the above, one of the most basic features of a DataFrame is to just display the data in a nice table.
There is much more to DataFrames, however. Let’s check some of that out…
Referencing Data in DataFrames
Let’s say that we want to view a subset of the data in a dataframe. For example, if we wanted to work with just the series that deals with ages from our Karate dataframe, we could do this:
>>> karate["age"] 0 52 1 56 2 49 3 17 4 14 5 14 6 12 7 12 8 12 Name: age, dtype: int64
This gives us our nice Series back.
DataFrames also allow us to query the data. For example, if we wanted to view all the elements of the DataFrame where the age is greater than 20…
>>> karate[age>20] age gender rank 0 52 F 20 1 56 M 18 2 49 M 14
We can also run some basic statistics on the overall dataframe like so…
>>> karate.describe()
age rank
count 9.000000 9.000000
mean 26.444444 12.222222
std 19.558317 6.418290
min 12.000000 0.000000
25% 12.000000 11.000000
50% 14.000000 14.000000
75% 49.000000 15.000000
max 56.000000 20.000000
Again, this is just the tip of the iceberg. Check out the docs for more: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
Visualizing DataFrames
On of the last things that I want to mention is that the DataFrame object does have the ability to do some data visualization. Check out the following example:
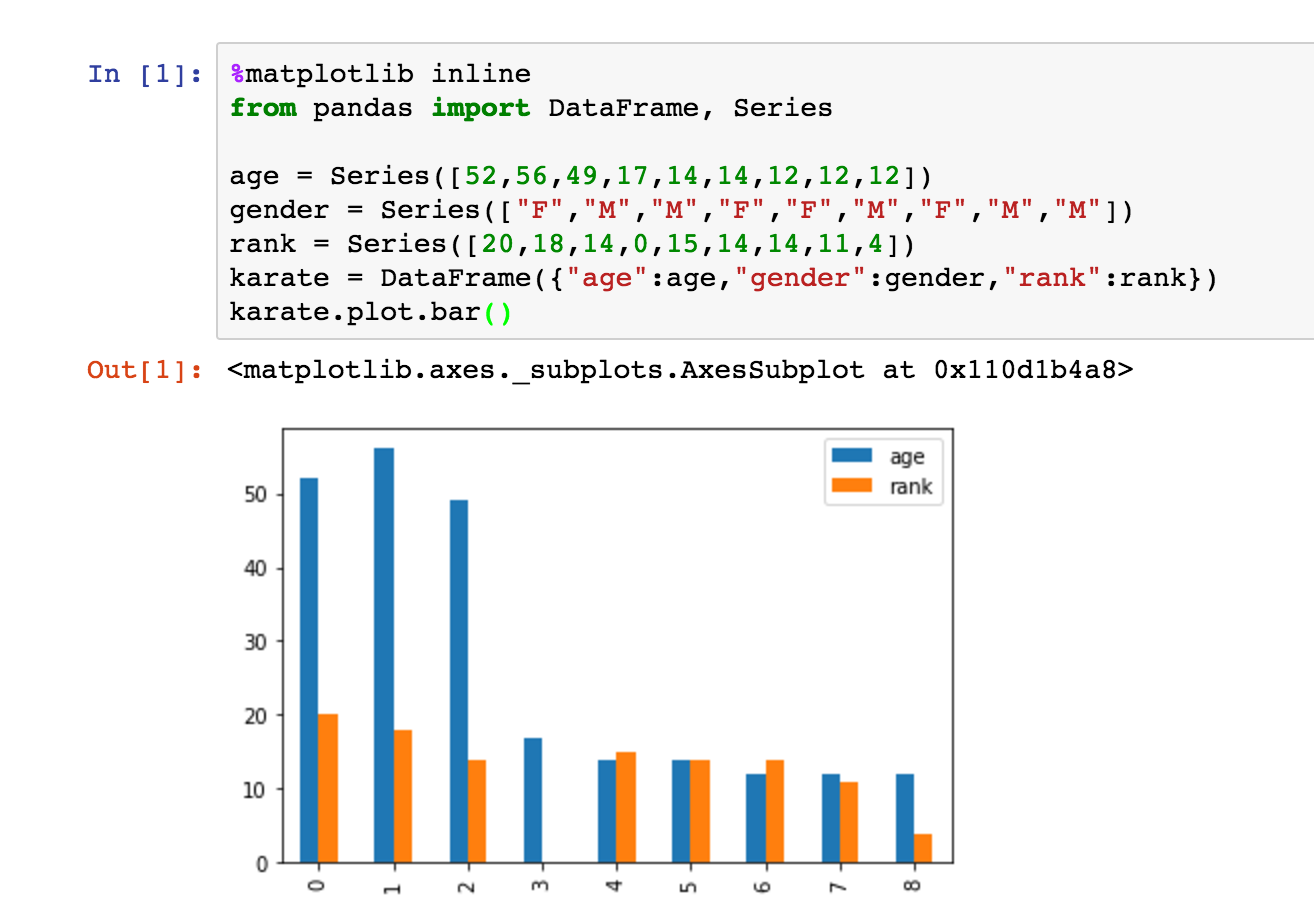
Conclusion
THe first chapter of the udacity Introduction to Data Science went over these and many other interesting features of pandas and numpy. For more info on these topics, check out the above links, or the Udacity course. It is free, BTW.
Looking forward
The next section of the course has to do with dealing with data from various files. I used the panda read from file feature to load data in the past. Check back soon for more info on that topic.